
O Google lançou um novo sistema de classificação chamado Term Weighting BERT (TW-BERT), que se destaca por aprimorar os resultados da pesquisa e ser simples de integrar em sistemas de classificação já em uso.
Apesar de não ter sido confirmado pelo Google, o uso do TW-BERT representa um avanço significativo na melhoria dos processos de classificação em diversas áreas, como na expansão de consultas. Além disso, sua fácil implementação facilita seu uso, na minha opinião.
TW-BERT conta com vários colaboradores, incluindo Marc Najork, renomado pesquisador do Google DeepMind e ex-diretor sênior de engenharia de pesquisa no Google Research.
Ele colaborou em várias pesquisas abordando assuntos relativos aos processos de categorização, assim como em diversas outras áreas.
Marc Najork é um dos coautores mencionados nos artigos.
- Melhorar as métricas Top-K para modelos de classificação neural – 2022.
- Abordagens de linguagem dinâmica para conteúdo em constante mudança – 2021.
- Repensando a busca: Transformando amadores em especialistas no assunto – 2021.
- Reformulação de recursos para modelos de classificação neural – 2020
- Aquisição de conhecimento com BERT no TF-Ranking – 2020.
- Reunião de palavras com significado para documentos de longo prazo – 2019
- TF-Ranking é uma biblioteca escalável do TensorFlow para aprendizagem de máquina lançada em 2018.
- O Marco LambdaLoss para Otimização de Métricas de Classificação – 2018
- Aprender a Classificar com Preconceito de Seleção em Pesquisa Pessoal – 2016
O que significa TW-BERT?
TW-BERT é uma estrutura de classificação que atribui pesos às palavras em uma consulta de pesquisa para identificar de forma mais precisa quais documentos são pertinentes para aquela busca.
O TW-BERT também se mostra eficaz na ampliação de consultas.
A Expansão de Consulta consiste em modificar uma consulta de pesquisa existente ou adicionar termos adicionais a ela (por exemplo, incluir a palavra “receita” na busca por “sopa de galinha”) com o objetivo de aprimorar a correspondência entre a consulta e os documentos pesquisados.
Incluir sinais de pontuação na pesquisa auxilia na identificação mais precisa do tema da pesquisa.
Texto parafraseado: Paradigmas de Recuperação de Informações com Duas Pontes TW-BERT.
O artigo de pesquisa aborda duas abordagens distintas de investigação: uma fundamentada em dados estatísticos e outra que se apoia em modelos de aprendizado profundo.
O texto discute os pontos positivos e negativos de métodos variados e propõe o TW-BERT como uma solução que combina as vantagens de ambos sem apresentar nenhuma desvantagem.
Eles estão redigindo.
Esses métodos estatísticos de recuperação oferecem uma busca eficaz que aumenta conforme o tamanho do conjunto de dados e se aplica a diferentes áreas.
No entanto, os termos são avaliados separadamente e não levam em conta o contexto completo da pesquisa.
Os estudiosos notam que os modelos de aprendizado profundo têm a capacidade de identificar o contexto das buscas realizadas.
Dá-se uma explicação:
Os modelos de aprendizado profundo têm a capacidade de contextualizar as consultas para oferecer representações aprimoradas de termos específicos.
Os pesquisadores estão sugerindo utilizar TW-Bert para completar ambos os métodos.
O progresso é detalhado.
“Nós utilizamos esses dois modelos para identificar quais termos de busca são considerados relevantes ou irrelevantes durante a pesquisa…”
Posteriormente, esses critérios podem ser ajustados para cima ou para baixo, a fim de aprimorar a eficácia do nosso mecanismo de busca.
Exemplo de Peso do Termo de Pesquisa no TW-BERT.
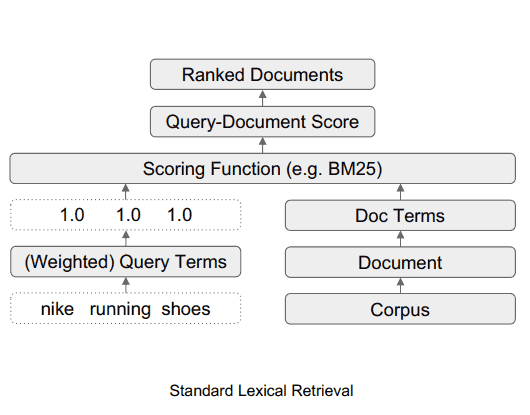
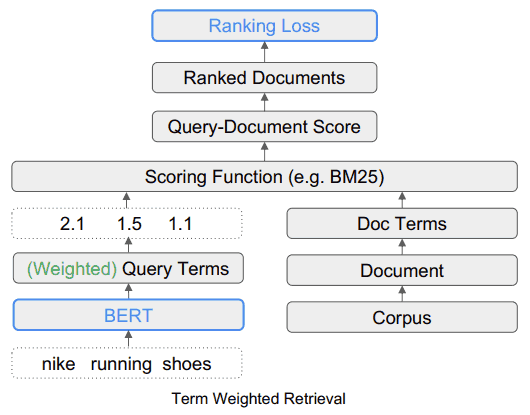
O artigo de pesquisa menciona como exemplo a busca por “tênis de corrida da Nike”.
De maneira simplificada, o algoritmo de classificação precisa interpretar corretamente as três palavras “Nike running shoes” conforme a intenção do pesquisador.
Eles afirmam que ao dar destaque à palavra “running” na busca, irão aparecer resultados irrelevantes que incluem marcas distintas da Nike.
Neste caso, a presença da palavra Nike nas páginas web do candidato é fundamental para o processo de classificação, destacando a importância da marca Nike.
Páginas web candidatas são aquelas que estão sendo avaliadas para aparecer nos resultados da busca.
A função do TW-BERT é atribuir uma pontuação (conhecida como ponderação) para cada segmento da consulta de pesquisa, de forma a torná-la compreensível da mesma maneira que uma pessoa que realizou a busca originalmente a entenderia.
Neste caso específico, a relevância da palavra Nike é destacada, por isso é necessário atribuir-lhe uma pontuação mais elevada (mais peso).
Os estudiosos redigem:
Assim, a questão é assegurar que a Nike seja considerada de forma significativa, ao mesmo tempo em que continuamos a oferecer calçados esportivos de corrida nos resultados finais obtidos.
O desafio adicional é compreender o contexto das palavras “running” e “shoes”, priorizando a união das duas como uma expressão, “sapatos de corrida”, ao invés de analisá-las separadamente.
A explicação deste problema e sua solução são fornecidas.
O segundo ponto a considerar é a maneira de destacar termos de n-grama mais relevantes durante a avaliação.
Na nossa pesquisa, os termos “corrida” e “calçados” são considerados separadamente, o que pode resultar em termos como “meias para correr” ou “tênis para patinação”.
Neste exemplo, pretendemos que nosso sistema de recuperação opere em um nível de termos n-grama para destacar a importância de “tênis de corrida” durante a classificação.
Restrições de resolução presentes nos painéis atuais.
O texto destaca que o método tradicional de ponderação em pesquisas é considerado restrito em relação às diferentes consultas. Além disso, aponta que os métodos de ponderação estatística têm um desempenho inferior em situações de baixa recorrência.
Zero-shot Learning é quando um modelo consegue resolver um problema para o qual não foi especificamente treinado.
Também é apresentado um resumo das restrições naturais dos métodos atuais de ampliação do conceito.
A ampliação do significado ocorre quando sinônimos são empregados para obter mais resultados em pesquisas ou quando se sugere outra palavra.
Por exemplo, se alguém busca por “sopa de galinha”, é entendido como se estivesse procurando por “receita de sopa de galinha”.
Eles abordam as limitações dos métodos atuais.
“Essas funções de pontuação secundárias não implicam em etapas adicionais de avaliação realizadas por funções de pontuação presentes em sistemas de busca convencionais, como estatísticas de consulta, estatísticas de documentos e valores de hiperparâmetros.”
Isso pode modificar a distribuição inicial de importância dos termos durante a avaliação final e busca.
Em seguida, os especialistas explicam que a aprendizagem profunda apresenta desafios em termos de complexidade na implementação e comportamento imprevisível ao ser aplicada em novas áreas sem treinamento prévio.
Portanto, é nesse momento que TW-BERT se torna relevante.
Duas Abordagens para a Implementação de Pontes no TW-BERT
A proposta apresentada é similar a uma abordagem combinada.
Na frase mencionada, a sigla IR se refere ao processo de Recuperação de Informações.
Eles estão redigindo.
Para completar a lacuna, combinamos a força dos sistemas de recuperação de palavras existentes com as representações de contexto de texto oferecidas por modelos avançados.
Os recuperadores Lexical já permitem a definição de pesos para os termos de pesquisa n-grama durante o processo de recuperação.
Nesta etapa do processo, utilizamos um modelo de linguagem para atribuir a devida importância aos termos n-grama da consulta.
O TW-BERT é ajustado de forma integral utilizando as mesmas métricas de avaliação empregadas no processo de recuperação, assegurando assim a congruência entre o treinamento e a recuperação.
Isso resulta em melhorias na recuperação ao utilizar o TW-BERT, que atribui pesos aos termos, mantendo a infraestrutura de IR semelhante à já existente.
O algoritmo TW-BERT atribui pesos às consultas para melhorar a precisão da pontuação de relevância, a qual é utilizada no processo de classificação.
Padrão de Recuperação Lexical
Termo de Recuperação Ponderado (TW-BERT)
TW-BERT pode ser facilmente implementado.
Uma das vantagens do TW-BERT é a possibilidade de ser facilmente integrado ao processo atual de classificação e recuperação de informações, sendo um componente que pode ser adicionado sem dificuldades.
Os especialistas redigem:
Isso nos possibilita inserir os valores de importância dos termos diretamente em um sistema de recuperação de informações.
Isso contrasta com métodos anteriores de ponderação, que exigem ajustes adicionais nos parâmetros de um mecanismo de busca para alcançar o melhor desempenho de recuperação, já que eles ajustam os pesos de termos por meio de heurísticas em vez de otimizar o processo como um todo.
O aspecto relevante dessa facilidade de implementação é que não é necessário utilizar software específico ou realizar atualizações no hardware para integrar o TW-BERT a um algoritmo de classificação.
O Google está implementando o TW-BERT em seu algoritmo de classificação?
Implantar o TW-BERT é simples, como já foi mencionado anteriormente.
Em minha visão, acredito que a probabilidade de o Google adotar esse framework em seu algoritmo aumenta conforme sua implantação se torna mais simples.
Isso quer dizer que o Google poderia incluir o TW-BERT na seção de classificação do algoritmo sem precisar realizar uma atualização completa do algoritmo principal.
Além da facilidade de implementação, outra maneira de identificar se um algoritmo pode estar sendo utilizado é avaliar seu desempenho em superar o estado da técnica atual.
Muitas pesquisas não alcançam sucesso significativo ou não trazem melhorias. Embora esses algoritmos sejam intrigantes, é provável que não sejam incorporados ao algoritmo do Google.
Os indivíduos que despertam interesse são os que alcançam grande sucesso, como é o caso do TW-BERT.
TW-BERT tem sido altamente eficaz. Foi mencionado que é simples integrá-lo em um algoritmo de classificação já existente e que ele se destaca, assim como os “dense rankers neurais”.
Os pesquisadores forneceram uma explicação sobre a maneira como os sistemas de classificação atuais podem ser aprimorados.
“Com a utilização desses sistemas de recuperação, conseguimos demonstrar que nosso método de ponderação de termos é mais eficaz do que as estratégias tradicionais de ponderação de termos em tarefas específicas dentro do campo de estudo.”
Em atividades que estão além de sua área de atuação, o TW-BERT aprimora as estratégias de peso básico, assim como os classificadores neurais densos.
Adicionalmente, demonstramos a eficácia do nosso modelo ao combiná-lo com modelos de ampliação de consultas já existentes, resultando em uma melhoria no desempenho em comparação com a busca convencional e a recuperação densa em situações de zero resultados.
Isso nos inspira a acreditar que nosso trabalho pode contribuir para aprimorar os sistemas de recuperação já existentes, reduzindo ao máximo o atrito nas bordas.
Portanto, esses são dois motivos sólidos pelos quais o TW-BERT já pode ser integrado ao algoritmo de classificação do Google.
- É uma atualização de toda a placa de classificação para quadros existentes.
- Pode ser facilmente colocado em prática.
Caso o TW-BERT tenha sido incorporado pelo Google, isso poderia ser a razão por trás das variações nas posições de busca que foram observadas pelas ferramentas de SEO e profissionais de marketing digital recentemente.
Normalmente, o Google divulga apenas certas alterações de classificação, especialmente quando têm um impacto significativo, como no caso do anúncio do algoritmo BERT.
Sem uma confirmação oficial, só podemos fazer suposições sobre a possibilidade de o TW-BERT estar incluído no algoritmo de classificação de pesquisas do Google.
Entretanto, a TW-BERT é uma estrutura impressionante que aparenta aprimorar a acurácia dos sistemas de busca de informações e pode estar sendo utilizada pela Google.
Dê uma olhada no artigo científico original.
Peso final do termo de consulta em formato PDF.
Estudo realizado pela página da Web do Google.
Significado de Consulta Detalhada Ponderosa.
Ilustração destacada fornecida por Shutterstock/TPYXA.




