Documento vazado do Google reconhece a superioridade da inteligência artificial de código aberto.

Um documento interno do Google vazou, apresentando um resumo detalhado sobre as razões pelas quais a empresa está sendo superada na área de inteligência artificial de código aberto. Além disso, sugere um plano para recuperar a liderança e controlar a plataforma.
O memorando começa reconhecendo que o concorrente nunca foi a OpenAI e sempre será de código aberto.
Não consegue rivalizar com o software de código aberto.
Além disso, reconhecem que não possuem a estrutura necessária para competir com o software de código aberto, admitindo que já perderam a batalha pela liderança na inteligência artificial.
Eles redigiram um texto.
Analisamos cuidadosamente as ações da OpenAI em busca de pistas sobre quem alcançará o próximo avanço significativo e qual será o próximo movimento a ser feito.
Porém, a realidade incômoda é que não estamos preparados para vencer essa competição de armas ou contra o OpenAI. Enquanto estávamos perdendo força, uma terceira parte tem se beneficiado silenciosamente em nossa desvantagem.
Estou me referindo, é claro, ao conceito de código aberto.
Certamente, eles estão nos ajudando a melhorar. As questões que costumávamos considerar como “principais desafios em aberto” estão sendo resolvidas e agora estão sob responsabilidade das pessoas.
A maior parte do memorando é dedicada a explicar como o Google é influenciado pelo uso de código aberto.
Mesmo que o Google tenha uma pequena superioridade em relação à fonte aberta, o autor do memorando admite que está perdendo e não retornará mais.
A autoavaliação dos cartões simbólicos que receberam é bastante deficiente.
Nossos modelos ainda estão um pouco à frente em qualidade, mas a diferença está diminuindo de forma surpreendentemente rápida.
Os modelos de código aberto são mais eficientes, mais adaptáveis, mais confidenciais e igualmente competentes.
Eles estão realizando tarefas com um orçamento de $100 e 13 bilhões de parâmetros, enquanto nós lidamos com um orçamento de 10 milhões e 540 bilhões.
Eles estão realizando essa tarefa em um curto período de tempo, semanas e não meses.
O tamanho grande da língua não é benéfico.
Uma das conclusões mais assustadoras destacadas no documento é que o tamanho do Google já não é uma vantagem.
Atualmente, considera-se que o grande tamanho externo de seus modelos é uma desvantagem, e não mais uma vantagem incontestável como antes acreditavam.
O documento vazado menciona uma série de ocorrências que indicam que o domínio do Google (e do OpenAI) sobre a inteligência artificial pode ser encerrado em breve.
Ele relata que há cerca de um mês, em março de 2023, foi divulgado um modelo de linguagem de código aberto de grande escala desenvolvido pela Meta chamado LLaMA.
Em poucos dias e semanas, a comunidade global de código aberto criou todas as ferramentas necessárias para produzir clones de Bard e ChatGPT.
Passos avançados, como ajuste de instrução e aplicação de feedback humano para reforço, foram prontamente reproduzidos pela comunidade global de código aberto, a um custo mais acessível.
- Ajuste preciso de um modelo de linguagem para que possa executar uma tarefa específica para a qual não foi originalmente treinado.
- Refinar a aprendizagem do feedback humano (RAFH) é uma abordagem na qual os indivíduos avaliam as respostas geradas por modelos de linguagem, a fim de identificar quais respostas são consideradas adequadas pelos seres humanos.
A técnica RLHF é empregada pela OpenAI na criação do InstructGPT, um modelo que serve de base para o ChatGPT e capacita os modelos GPT-3.5 e GPT-4 a receberem instruções e realizarem tarefas.
RLHF é a chama que foi obtida pela fonte aberta.
Título: Google is Worried About the Open Source Scale
O Google está preocupado especialmente com a capacidade do movimento Open Source de ampliar seus projetos de uma maneira que o software proprietário não consegue.
Os dados de resposta utilizados para desenvolver o clone de código aberto do ChatGPT, Dolly 2.0, foram elaborados exclusivamente por uma grande equipe de voluntários.
Google e OpenAI confiavam em parte na coleta de perguntas e respostas de sites como Reddit.
O dataset de perguntas e respostas de código aberto desenvolvido pela Databricks é reconhecido por sua alta qualidade devido à contribuição de profissionais na sua criação, resultando em respostas mais detalhadas e substanciais em comparação com conjuntos de dados convencionais provenientes de fóruns públicos.
O memorando vazado que foi observado.
No começo de março, a comunidade de código aberto recebeu o seu primeiro modelo de fundação eficaz, com o vazamento do LLaMA de Meta para o público.
Não havia orientações, diálogos ou comunicação real.
No entanto, a comunidade prontamente compreendeu o significado do que havia sido transmitido.
Houve então um grande fluxo de ideias inovadoras, com apenas alguns dias entre os principais avanços…
Estamos agora há cerca de um mês e já surgiram diferentes variantes com modificações em termos de instrução, quantização, aprimoramento de qualidade, interações humanas, multimodalidade, RLHF, entre outros, muitos dos quais se baseiam uns nos outros.
Além disso, eles encontraram uma solução para o problema de escala, permitindo que qualquer pessoa possa participar.
Muitas das ideias inovadoras vêm de indivíduos comuns.
A barreira que impedia o acesso ao treinamento e experimentação foi reduzida de uma grande organização de pesquisa para apenas uma pessoa, uma noite e um computador portátil.
Em resumo, aquilo que demandou meses e anos para ser treinado e construído pelo Google e OpenAI foi realizado pela comunidade de código aberto em questão de dias.
Isso deve ser uma situação muito preocupante para o Google.
É um dos motivos pelos quais tenho dedicado tanto tempo a escrever sobre o movimento de inteligência artificial de código aberto, pois parece ser onde o desenvolvimento futuro da inteligência artificial generativa estará concentrado em um futuro próximo.
A fonte aberta tem sido historicamente mais bem-sucedida do que a fonte fechada.
O memorando menciona a experiência recente com o DALL-E da OpenAI, um modelo de aprendizado profundo usado para gerar imagens, e compara com a fonte aberta Stable Diffusion, indicando o que está acontecendo atualmente na Inteligência Artificial Generativa, como o Bard e o ChatGPT.
Dall-e, desenvolvido pela OpenAI em janeiro de 2021, foi seguido por Stable Diffusion, sua versão de código aberto, que foi lançada em agosto de 2022. Em poucas semanas, Stable Diffusion ultrapassou a popularidade de Dall-e.
Este gráfico de linha temporal demonstra como a disseminação estável ultrapassou o Dall-E.
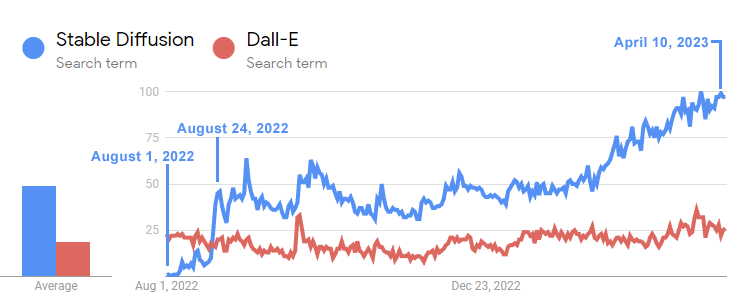
A linha temporal no Google Trends ilustra como o interesse no modelo de difusão estável de código aberto rapidamente ultrapassou o interesse por Dall-E em apenas três semanas após seu lançamento.
Apesar de Dall-E ter estado ausente por um ano e meio, o interesse pela Difusão Estável continuou crescendo rapidamente, ao passo que o desenvolvimento do Dall-E da OpenAI permaneceu sem avanços.
O Google está sendo assombrado por pesadelos de eventos semelhantes ultrapassando Bard (e OpenAI), representando uma ameaça existencial.
A criação do modelo de fonte aberta é considerada mais eficiente.
Outro aspecto que preocupa os engenheiros do Google é a rapidez e o baixo custo do processo de desenvolvimento e aprimoramento de modelos de código aberto, que se encaixa bem em uma abordagem colaborativa global típica de projetos desse tipo.
O memorando observa que novas técnicas, como a LoRA (Adaptação de Grandes Modelos de Linguagem), permitem o ajuste fino de modelos de linguagem em questão de dias com custo extremamente baixo, com o LLM final comparável aos LLMs extremamente mais caros criados pelo Google e OpenAI.
Outro benefício é que os engenheiros de código aberto podem construir em cima do trabalho anterior, iterar, em vez de ter que começar do zero.
Construir modelos linguísticos grandes com bilhões de parâmetros da maneira que o OpenAI e o Google têm feito não é necessário hoje.
O que pode ser o ponto de que Sam Alton recentemente estava insinuando quando ele disse recentemente que a era de grandes modelos de idiomas maciços acabou.
O autor do memorando do Google contrastou a abordagem LoRA barata e rápida para criar LLMs contra a abordagem AI grande atual.
O autor do memo reflete sobre a falta do Google:
“Por contraste, treinar modelos gigantes do zero não só joga fora o pré-treinamento, mas também quaisquer melhorias iterativas que foram feitas no topo. No mundo de código aberto, não demora muito antes que essas melhorias dominem, fazendo um retrete completo extremamente caro.
Devemos ser atenciosos sobre se cada nova aplicação ou ideia realmente precisa de um novo modelo.
De fato, em relação ao tempo dedicado à engenharia, a velocidade de aprimoramento desses modelos é muito superior àquela que conseguimos alcançar com nossas versões mais avançadas, e a qualidade já está quase idêntica à do ChatGPT.
O autor conclui com a compreensão de que o que eles pensavam ser sua vantagem, seus modelos gigantes e custos proibitivos concomitantes, foi na verdade uma desvantagem.
A colaboração global na Open Source torna a inovação muito mais eficaz e acelerada em grande escala.
Como pode um sistema de código fechado competir contra a multidão esmagadora de engenheiros em todo o mundo?
O escritor finaliza afirmando que eles não conseguem rivalizar e que a competição direta é, de acordo com ele, uma ideia sem sucesso.
Essa é a crise, a tempestade, que está se desenvolvendo fora do Google.
Se você não consegue programar em código aberto, junte-se a eles…
A única consolação que o autor do memo encontra em código aberto é que porque as inovações de código aberto são gratuitas, o Google também pode aproveitar isso.
Por último, o autor conclui que a única abordagem aberta ao Google é possuir a plataforma da mesma forma que dominam as plataformas Chrome e Android de código aberto.
Eles destacam os benefícios que a Meta está obtendo ao disponibilizar seu extenso modelo de linguagem LLaMA para pesquisa, e como agora contam com milhares de pessoas realizando seu trabalho sem custos.
Talvez o grande takeaway do memo então é que o Google pode, no futuro próximo, tentar replicar seu domínio open source, liberando seus projetos em uma base de código aberto e, assim, possuir a plataforma.
O memo conclui que ir open source é a opção mais viável:
“O Google deve estabelecer-se um líder na comunidade open source, tomando a liderança cooperando com, em vez de ignorar, a conversa mais ampla.
Isso pode envolver a adoção de medidas desconfortáveis, como divulgar os pesos do modelo para pequenas variações ULM. Isso implica em abrir mão de parte do controle sobre nossos modelos.
Mas este compromisso é inevitável.
Não podemos esperar tanto impulsionar a inovação quanto controlá-la. ”
Open Source Caminhadas para longe com o fogo AI
Na semana passada fiz uma alusão ao mito grego do herói humano Prometheus roubando fogo dos deuses no monte Olympus, colocando a fonte aberta para Prometheus contra os “deus olympian” do Google e OpenAI:
Eu tweetei:
“Enquanto o Google, a Microsoft e a IA Aberta brigam entre si e têm suas costas desligadas, o Open Source está andando com seu fogo? ”
O vazamento do memo do Google confirma que a observação, mas também aponta para uma possível mudança de estratégia no Google para se juntar ao movimento de código aberto e, assim, cooptar e dominá-lo da mesma forma que fizeram com o Chrome e o Android.
Leia o memorando do Google vazado aqui:
Google “Não temos carne, nem OpenAI”




