
A Microsoft divulgou um estudo que revela como técnicas avançadas de incentivo podem levar um AI generalista, como o GPT-4, a ter um desempenho igual ou superior a um AI especializado em um tema específico. Os pesquisadores conseguiram ajustar o modelo Med-PaLM 2 do GPT-4, que havia sido treinado especificamente para esse tópico.
Estratégias Avançadas de Estímulo
Os achados deste estudo validam as descobertas feitas por utilizadores experientes de inteligência artificial generativa, os quais estão aplicando esses conhecimentos para criar imagens impressionantes ou conteúdo textual.
O prompting avançado, também chamado de engenharia rápida, é fundamentado em princípios sólidos, conforme demonstrado pelos resultados da pesquisa. Alguns podem argumentar que o prompting não é tão profundo a ponto de justificar o nome de engenharia, mas as técnicas avançadas de prompting são embasadas em bases sólidas.
Por exemplo, o raciocínio Chain of Thought (CoT) é uma técnica utilizada por muitos usuários experientes de inteligência artificial generativa, que a aplicam de forma produtiva em suas pesquisas.
O Chain of Thought é um método desenvolvido pelo Google por volta de maio de 2022, o qual possibilita que a inteligência artificial divida uma tarefa em passos com base no processo de raciocínio.
No meu texto, falei sobre o estudo do Google que abordou a capacidade de uma inteligência artificial de dividir uma tarefa em passos para resolver uma variedade de problemas de palavras, inclusive de matemática, e desenvolver um raciocínio de senso comum.
Esses diretores exploraram como os usuários da IA generativa influenciaram a produção de conteúdo de alta qualidade, seja por meio da geração de imagens ou textos.
Peter Hatherley, criador das suítes de aplicativos web da Inteligência Autorizada, destacou a eficácia da abordagem de pensamento que ele promove.
A transformação do pensamento faz com que suas ideias, que são como sementes, se tornem algo surpreendente.
Peter também percebeu que ele inclui o Conhecimento de Tarefas em seus Geradores de Texto personalizados, com o objetivo de desafiá-los.
A linha de raciocínio (CoT) levou à constatação de que simplesmente solicitar algo a uma inteligência artificial generativa não é eficaz, pois o resultado obtido será sempre aquém do desejado.
O prompting CoT define os caminhos que a inteligência artificial geradora deve seguir para alcançar o resultado desejado.
A pesquisa avançou ao combinar o raciocínio CoT com outras duas técnicas, resultando em níveis de qualidade surpreendentes que ultrapassaram as expectativas anteriores.
Esse método é conhecido como Medprompt.
O texto destaca a importância da demonstração do valor das técnicas avançadas de prompt.
Os pesquisadores experimentaram sua técnica em quatro tipos distintos de fundação.
- Texto: 540B Flan-PaLM
- Reescreva o texto “Med-PaLM 2” de forma diferente.
- GPT-4: Versão mais recente do modelo de linguagem GPT.
- GPT-4 MedPrompt es el nombre del texto que deseas parafrasear.
Eles utilizaram conjuntos de dados de referência desenvolados para avaliar o conhecimento médico, incluindo testes de raciocínio e questões de exames médicos.
Quatro grupos de informações médicas de base.
- Recursos educacionais em PDF que respondem questões de múltipla escolha com base em um conjunto de dados.
- Conjunto de dados PubMedQA disponível em formato PDF com perguntas e respostas que podem ser respondidas com Sim, Não ou Talvez.
- Texto: Base de dados MedMCQA em formato PDF, que contém questões de múltipla escolha de várias disciplinas.
- Este grupo de dados inclui 57 tarefas abrangendo diferentes áreas nos campos das Humanidades, Ciências Sociais e STEM (ciência, tecnologia, engenharia e matemática). Os pesquisadores se concentraram apenas nas tarefas relacionadas à área da medicina, abordando temas como conhecimento clínico, genética médica, anatomia, prática médica, biologia universitária e medicina.
O desempenho do GPT-4 com o uso do Medprompt superou significativamente o de todos os concorrentes testados em quatro conjuntos de dados médicos diferentes.
A tabela demonstra como o Medprompt superou outros modelos de fundação em pontuação.
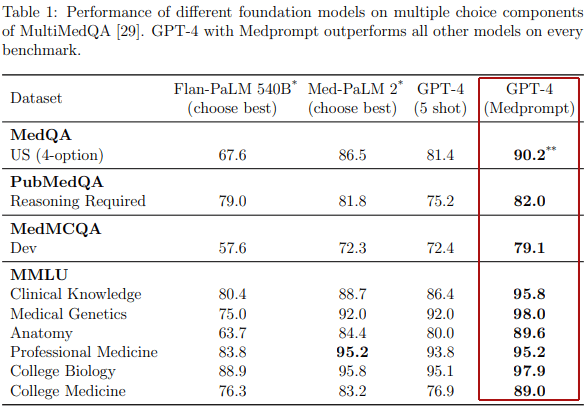
Importância do Medprompt.
Os pesquisadores observaram que a aplicação do raciocínio CoT, aliado a outras técnicas de estímulo, poderia capacitar um modelo básico a se equiparar a modelos especializados de desempenho GPT-4, os quais foram treinados exclusivamente em um único domínio.
A pesquisa é importante para todos os usuários de inteligência artificial generativa, pois a técnica MedPrompt pode ser aplicada em diversas áreas de conhecimento, não se restringindo apenas ao campo médico.
As consequências dessa descoberta indicam que não é preciso investir grandes quantidades de recursos na construção de um modelo de linguagem extenso para se tornar especialista em uma área específica.
Basta seguir os princípios do Medprompt para alcançar um ótimo resultado na criação de inteligência artificial generativa.
Três Táticas de Estímulo
Os pesquisadores delinearam três métodos de aviso.
- Escolha ativa de um pequeno número de disparos.
- Sequência de pensamentos que surgem espontaneamente.
- Opte pela opção shuffle de maneira semelhante.
Escolha ativa de um reduzido número de disparos.
A seleção de poucos exemplos durante o treinamento permite que o modelo de inteligência artificial escolha exemplos significativos de forma dinâmica.
A aquisição de um pequeno número de exemplos é uma abordagem eficaz para o modelo básico aprender e se ajustar a tarefas específicas.
Neste método, os modelos são treinados com um conjunto de exemplos pequeno em comparação com bilhões de exemplos, com a intenção de que esses exemplos sejam um reflexo abrangente de várias questões importantes dentro do domínio de conhecimento.
Tradicionalmente, os especialistas geralmente produzem manualmente esses exemplos, porém é difícil assegurar que abranjam todas as situações possíveis. Uma alternativa conhecida como aprendizagem dinâmica de poucos tiros opta por exemplos que se assemelham às tarefas necessárias para o modelo resolver, os quais são selecionados de um conjunto de dados de treinamento extenso.
Na técnica Medprompt, os pesquisadores escolheram exemplos de treinamento que possuem semelhança semântica com um determinado caso de teste. Essa abordagem dinâmica se mostra mais eficaz do que os métodos convencionais, já que utiliza os dados de treinamento já existentes e não requer grandes atualizações para o modelo.
Sequência de pensamentos originados internamente.
A técnica de Cadeia de Pensamento Auto-Gerada emprega exemplos de linguagem natural para orientar o modelo de IA através de um processo de raciocínio sequencial, automatizando a geração de exemplos de cadeias de pensamento e eliminando a necessidade de depender de especialistas humanos.
O artigo de pesquisa aborda:
O método Chain-of-thought (CoT) emprega frases em linguagem natural, como por exemplo “Vamos analisar de forma sequencial”, com o objetivo de encorajar o modelo de maneira direta a produzir uma sequência de etapas de raciocínio intermediárias.
Foi desenvolvida uma técnica para aprimorar consideravelmente a habilidade de modelos de fundação em realizar raciocínio complexo.
A maioria das estratégias para a elaboração de cadeias de pensamento se baseia na utilização de especialistas para desenvolver manualmente alguns exemplos de tiro com cadeias de pensamento para incentivar. Em vez de depender de especialistas humanos, buscamos um método para automatizar a geração de exemplos de cadeias de pensamento.
Encontramos a possibilidade de solicitar que o GPT-4 crie uma sequência de pensamentos para os exemplos de treinamento, simplesmente usando o prompt a seguir:
Os investigadores notaram que esse procedimento poderia gerar resultados incorretos, também conhecidos como resultados fantasiosos. Para resolver essa questão, decidiram solicitar que o GPT-4 realizasse uma etapa de confirmação extra.
Os pesquisadores realizaram o procedimento dessa maneira.
Uma dificuldade essencial com essa estratégia é que as conclusões lógicas autogeradas apresentam um potencial risco de conter argumentos ilógicos ou equivocados.
Reduzimos essa preocupação ao fazer com que o GPT-4 produza tanto uma lógica quanto uma previsão da resposta mais provável que seguirá esse processo de pensamento.
Se a resposta não estiver de acordo com a verdade do solo, a amostra será rejeitada, pois não podemos confiar no raciocínio utilizado.
Apesar de um pensamento delirante ou incorreto ainda poder levar a uma resposta correta final (ou seja, falsos positivos), observamos que essa etapa simples de confirmar os rótulos serve como um eficiente filtro para evitar falsos negativos.
Opte por um Conjunto de Embaralhamento.
Uma questão relacionada à resposta de perguntas de múltipla escolha é que os modelos de inteligência artificial, como o GPT-4, podem apresentar parcialidade na escolha das respostas.
Tradicionalmente, o preconceito de posição refere-se à inclinação natural das pessoas em escolher as opções mais altamente classificadas em uma lista de escolhas.
Por exemplo, foi observado que, ao serem apresentados com uma lista de resultados de pesquisa, a maioria dos usuários tende a escolher os resultados mais bem classificados, mesmo que esses resultados estejam incorretos. De forma surpreendente, os modelos de fundação mostram o mesmo padrão de comportamento.
Os pesquisadores desenvolveram uma abordagem para lidar com o viés de posição que surge ao responder a uma pergunta de múltipla escolha no contexto de um modelo de fundação.
Essa estratégia amplia a variedade de respostas ao superar o fenômeno conhecido como “decodificação heurística”, que é a tendência dos modelos de base, como o GPT-4, de selecionar a palavra ou frase mais provável em um conjunto de opções.
Em um processo de decodificação ambicioso, em cada passo de produção de uma sequência de palavras (ou em relação a uma imagem, pixels), o modelo seleciona a palavra/frase/pixel mais provável (também conhecida como token) com base no contexto presente.
O modelo toma decisões em cada fase sem levar em conta o efeito no conjunto final.
A seleção do Ensemble de Embaralhamento aborda duas questões.
- Influência da perspectiva
- Interpretação da elegância.
Dessa forma é esclarecido:
Sugerimos diminuir a influência desse preconceito ao limitar as opções disponíveis e depois avaliar se as respostas são consistentes para as diferentes ordens de classificação na escolha de múltiplas opções.
Dessa forma, optamos por aplicar a seleção aleatória e a auto-consistência como medida preventiva. A auto-consistência substitui a abordagem ingênua de caminho único ou decodificação gananciosa por um conjunto variado de caminhos de raciocínio, quando solicitado várias vezes em uma temperatura acima de zero. Esse cenário introduz um elemento de aleatoriedade nas gerações.
Ao optarmos pela técnica de embaralhamento, reorganizamos a sequência das opções de resposta antes de criar cada linha de raciocínio. Posteriormente, escolhemos a resposta mais coerente, ou seja, aquela que é menos afetada pela reordenação das opções.
O embaralhamento de escolha traz uma vantagem extra ao ampliar a variedade de cada linha de pensamento, além de melhorar a qualidade do conjunto final, juntamente com a amostragem de temperatura.
Utilizamos essa estratégia na criação de etapas intermediárias de CoT para os exemplos de treinamento. Para cada exemplo, embaralhamos as opções várias vezes e geramos um CoT para cada possibilidade. Apenas mantemos os exemplos com a resposta certa.
Assim, ao limitar as opções e avaliar a coerência das respostas, essa abordagem não apenas diminui a predisposição, mas também melhora o desempenho nos conjuntos de dados de comparação, superando até mesmo modelos avançados como o Med-PaLM 2.
Alcance de sucesso em diferentes domínios por meio de estratégias de engenharia.
Finalmente, o que faz este estudo de pesquisa excepcional é que as descobertas não se limitam ao campo da medicina, podendo ser utilizadas em diversos contextos de conhecimento.
Os pesquisadores redigem:
Observamos que, embora o Medprompt apresente um desempenho excepcional em conjuntos de dados médicos de referência, o algoritmo é versátil e não se limita ao campo da medicina ou à resolução de questões de múltipla escolha.
Acreditamos que a abordagem de combinar a seleção cuidadosa de poucos exemplos, a cadeia de etapas de pensamento auto-geradas e o voto de maioria semelhante pode ser utilizada em diversos outros contextos de resolução de problemas, incluindo tarefas menos limitadas.
Esta conquista é significativa, pois implica que os resultados pendentes podem ser aplicados em praticamente qualquer assunto sem a necessidade de treinar intensamente um modelo em áreas específicas do conhecimento, o que demandaria tempo e recursos.
Qual é o significado de Medprompt para a IA Generativa?
A Medprompt apresentou uma nova forma de obter recursos de modelos aprimorados, tornando a inteligência artificial generativa mais flexível e capaz de se adaptar em diversos campos de conhecimento com menos necessidade de treinamento e esforço do que se pensava anteriormente.
As consequências para o futuro da inteligência artificial generativa são significativas, e também é importante considerar o impacto que isso pode ter na capacidade de desenvolver tecnologias rapidamente.
Confira o mais recente estudo acadêmico disponível.
Será que os modelos de fundação generalistas podem superar os modelos de ajuste especializado? Um estudo de caso na área da medicina.
Ilustração principal fornecida por Shutterstock/Asier Romero.




